2.4 Curve Fitting
The goal of this section is to derive a method which we can use to generate a best fit function
for given
points .
One constraint with the process presented in this section is that our best fit function
must be of
the form .
Our first step in deriving a method to find the desired best fit function is to understand a vector process called the
Gram-Schmidt Orthogonalization procedure.
Introduction to the Gram-Schmidt Orthogonalization Procedure
The goal of the Gram-Schmidt Orthogonalization procedure is to find a set of orthogonal vectors (section 2.3.2) which
exist in the same vector space as defined by a given set of vectors. In order to do this, we will use Figure 2.6.
and
are arbitrary vectors which exist
in a common vector space. is the
component of that exists in the vector
space with a basis defined by just .
is orthogonal to
. Our goal is to find
mathematical expressions for
and .
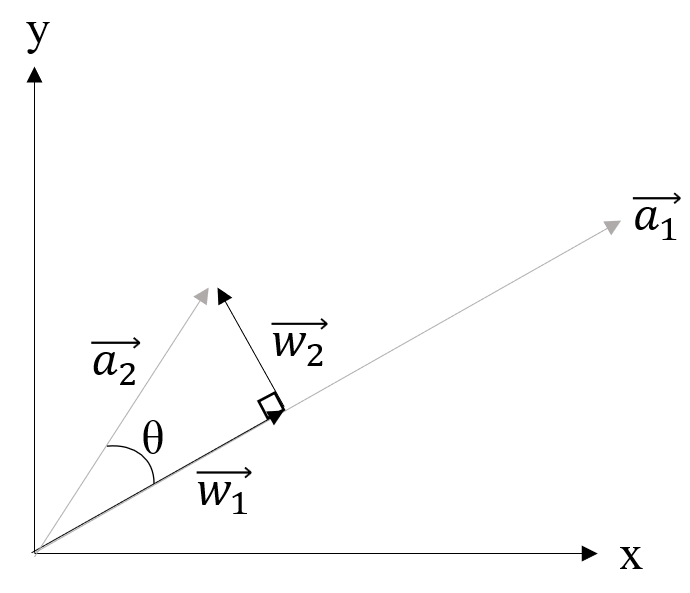
Let us start with .
Using geometry, we can state equation 2.202.
Plugging in equation 2.197 for ,
we get equation 2.203.
Simplifying equation 2.203 and plugging in the relation that
we are
left with equation 2.204.
Now, we know that
is simply equal to .
is orthogonal
to both and
. Therefore,
the vectors
and
constitute a set of orthogonal vectors that exist within the same vector space as the original
and
.
We have achieved our goal. We can extend this methodology to find an orthogonal vectors
within the same vector
space as input vectors .
This is shown in the following equation.
In the general equations provided,
is equal to the
shown in Figure 2.6. The big picture concept of the presented procedure is to force
to be orthogonal
to by subtracting
out components of
that are not orthogonal. This process can be repeated as many times as necessary to generate a full orthogonal set
.
Using the Gram-Schmidt Orthogonalization Procedure for Curve Fitting
As mentioned previously, for the method presented in this section, our best fit function must be of the form shown in
equation 2.205.
Plugging a given dataset
into equation 2.205, we get equation 2.206.
| (2.206) |
Essentially, the trick is to chose the correct
so that our is as close as possible
to the given . Please note that I
have transitioned from using the
notation for vectors and instead have shifted to large brackets in order to present the above equation in a
more intuitive form. In moving forward with this vector mindset, we will refer the vector with coefficient
as
. This logic can be
extrapolated to , while the
vector with components of
will be referred to as .
This is shown mathematically in equation 2.207.
You may notice that
can be thought of as constituting a vector space.
In order to find the desired
we first start out by building an orthogonal basis for the vector space defined by equation 2.207. In order to
do this, we can use the gram-schmidt orthogonalization procedure explained previously to transform
to the orthogonal
counterparts .
We then want to find the vector that exists within this basis that is “closest” to
. This vector will be defined as
. Mathematically, we can state that we
have found the correct when the dot
product of the difference between
and
() with
is 0. If this is confusing,
reference Figure 2.6, and imagine
is vector basis of ,
while is our true
. Thus, we state the closest any
vector within the vector space of
can get to is
a such
that .
is
in Figure
2.6. Thus, we get equation 2.208.
We can use equation 2.204 to find
for as
shown in equation 2.209.
Since
is build up from vectors that exist within our original vector space
(), we know that there
exists a combination of
that output this vector. These values are the solution to our problem. Therefore, we can use system of equation techniques to
solve equation 2.210 and obtain our coefficients of interest.
| (2.210) |
Using Matrix Techniques
The process presented in the previous section requires a considerable amount of work. First,
must be found. Later, a system of
equations needs to be solved for .
In this section, we will derive a matrix (section 2.6) process for finding
. The first step in doing
this is to recognize that
can be rewritten as
(therefore transforming
as a 1x3 matrix and
as a 3x1 matrix). Given this, we can rewrite equation 2.209 as shown in equation 2.211.
We can factor out
from equation 2.211 as shown in equation 2.212.
For simplicity, the vector term within the large brackets will be referred to as matrix
from
now on as shown in equation 2.213.
From equation 2.212, we can see that multiplication by the
matrix
transforms the given vector into the “closest” vector to the given vector that exists within the vector space built up of
.
Plugging
in we get equation 2.214.
We can expand upon this and say that the matrix
multiplied by any vector which exists with the vector space governed by the basis
will
simply equal that original vector.
From equation 2.212 we know that the matrix
is a summation of matrices of the form shown in equation 2.215.
Taking the transpose of equation 2.215, we get the equation 2.216.
Applying equation 2.268 to equation 2.216 we get equation 2.217.
Now, we know from equation 2.267 that a matrix double transposed simply equals the original matrix
.
Plugging this into equation 2.217 we get equation 2.218.
You may notice that equation 2.218 is equivalent to equation 2.215; this is the term we started with before we took the
transpose. Therefore, we can state equation 2.219.
We can multiply from
equation 2.207 by matrix
get equation 2.210.
As can be deduced, equation 2.220 simply consolidates the orthogonlization into the
matrix multiplication.
We can consolidate the
vectors to create matrix
and constants
to create matrix
as matrices as shown in equations 2.221 and 2.222.
| (2.221) |
| (2.222) |
Rewriting equation 2.220 using the matricies in equations 2.221 and 2.222 we get equation 2.223.
Now, our goal is to solve for .
Intuitively, it seems like we should multiply both sides of the equation by
.
However, going back to the definition of this matrix (2.221), we realize that this matrix will not always
be square. Therefore, our work-around solution is to multiply both sides of the above equation by
as shown
in equation 2.224.
Combining equation 2.267 with 2.268 we can simply equation 2.224 as shown in equation 2.225.
Substituting equation 2.219, we can simplify further as shown in equation 2.226.
We know that the vectors that constitute a
(reference equation 2.221) must exist in the vector space whose basis is
(since these basis vectors themselves are simply an orthogonalization of the vectors that constitute
).
Therefore, we can apply the mental exercise conducted in equation 2.214 to state that
. Given
this substitution, we can simply further as shown in equation 2.227.
Now, since is square, we can take
the inverse of this term to solve for .
Doing this, we end up with equation 2.228.
Short Example
In this example, we will start out with the given points ,
,
,
. We will
fit an equation of the form shown in equation 2.229 to the provided points.
As can be deduced, our task is to find the coefficients ,
, and
. Per laid
out process, our problem can be rewritten using equation 2.206 as shown in equation 2.230.
| (2.230) |
Performing the Gram-Schmidt organization procedure on the vectors provided in equation 2.230 (, , using previous terminology), we get the following.
We can find
using the equation 2.209 as shown in equation 2.231.
| (2.231) |
Now that we have found ,
we can assemble the equation laid out by 2.210 as shown in equation 2.232.
| (2.232) |
Solving the systems of equations provided within equation 2.232 for our unknowns, we get
,
, and
.
Plugging this into our original fitting equation (equation 2.229) we get equation 2.233.
As laid out previously, we can derive the same solution using matrix techniques. Applying equation 2.221 to this situation, we get
equation 2.234 .
| (2.234) |
Plugging in equation 2.234 along with the given
into equation 2.228 we get equation 2.235.
| (2.235) |
Solving, we end up with equation 2.236.
| (2.236) |
This result matches the result we obtained using the non-matrix method.
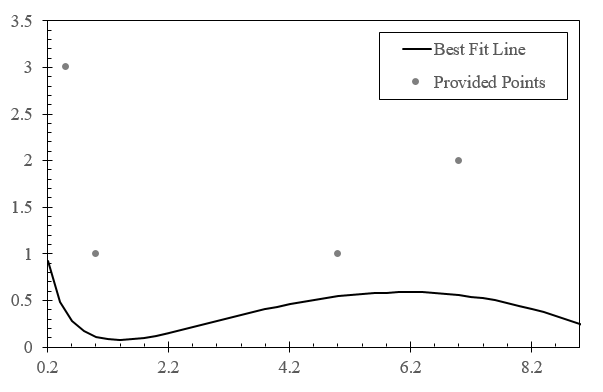
In Figure 2.7, a graph of 2.233 is provided along with the points provided in the problem statement.
2.4.1 R Squared
The
statistic is a tool to determine how closely our best fit function fits to the given data-set. This statistic is calculated using
equation 2.237.
In equation 2.237,
is the mean given
value.
corresponds to the best fit function whose generation has been detailed in section 2.4.
As can be deduced from equation 2.237, an
of
means that the best fit function perfectly models the data (goes through all the points). The closer the
statistic
is to , the
worse of a fit exists.
Short Example
In this example, we will generate an static for the example provided in section 2.4. As a reminder, we were provided the following data-set; , , , . We used this data-set to generate the following best fit equation.
We can use this data to generate Table 2.3.
Plugging this data into equation 2.237 we get an
value of .
The fact that this value is negative signifies that the data-set has a greater variation from the best fit function than from it’s
own mean.